|
Pathfinding, or path planning is everywhere in game AI. Whenever an AI is able to navigate through game world level, calculating a suitable and sensible route, it is called as Pathfinding. In this write-up, I will try to explain two major pathfinding algorithms; A* and Dijkstra and their implementation in C++.
Neither A* nor Dijkstra can work directly on the game level geometry. They rely on a simplified version of the level to be represented in the form of a graph. For pathfinding, we use directed non-negative weighted graphs. Graphs A graph is a mathematical structure represented diagrammatically. It consists of two different types of elements; nodes and edges/connections. A node is a place in the game world represented through the graph, and an edge represents a connection between two nodes. If a player can travel between node A and node B, there will be an edge representing this connection. Directed graphs represent movement in one direction. A weighted directed graph has a weight associated with each connection in the graph. So, if a player can travel from node A to node B and from node B to node A, there will be two edges representing two directions of movement and both will have a weight associated to them. This weight is usually the cost of traveling from one node to another. We use this cost to calculate the optimal path between two points. In its implementation, a graph will store a list of edges. Graph class will have a function that will return the outgoing edges from a given node. This function will be used in the pathfinding algorithms. 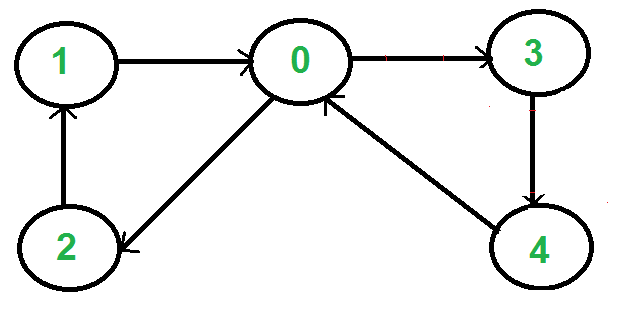
A sample directed graph with nodes and connections.
Game Structs
For the pathfinding algorithms, I am using the following structs in my code: 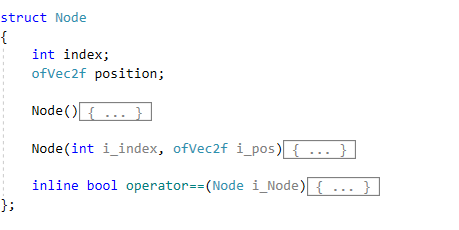
Node - To represent a node of the graph. It stores the position and index of the Node.
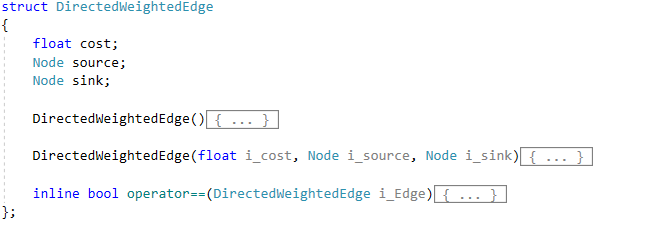
DirectedWeightedEdge - It stores the information regarding an edge of the graph.
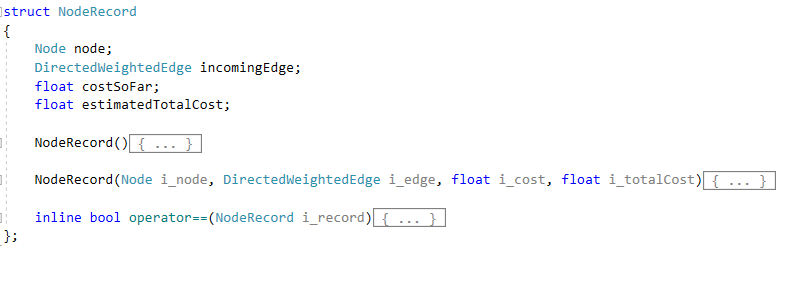
Node Record - It stores the information regarding a node that is required by the algorithms to calculate the path.
Dijkstra’s Algorithm
Dijkstra’s algorithm wasn’t originally designed for pathfinding as we do in games. It was intended to solve the ‘shortest path’ problem in mathematical graph theory. Dijkstra works by spreading out from the start node along its connections. It keeps the record of the direction it came from, and once it reaches the goal, it can follow back to the start point. Dijkstra works in iterations. At each iteration, it considers one node of the graph and follows its outgoing connections. The algorithm also keeps track of all the nodes it has seen in two lists; open and close. Open list stores all the nodes seen by the algorithm, but not yet processed. The close list contains all the nodes that have been processed by the algorithm. While following a connection from a current node, we assume that we will end up at an unvisited node. We can instead end up at an open or close node. We should take care of these edge cases differently. Below steps can be used to describe the Dijkstra’s Algorithm:
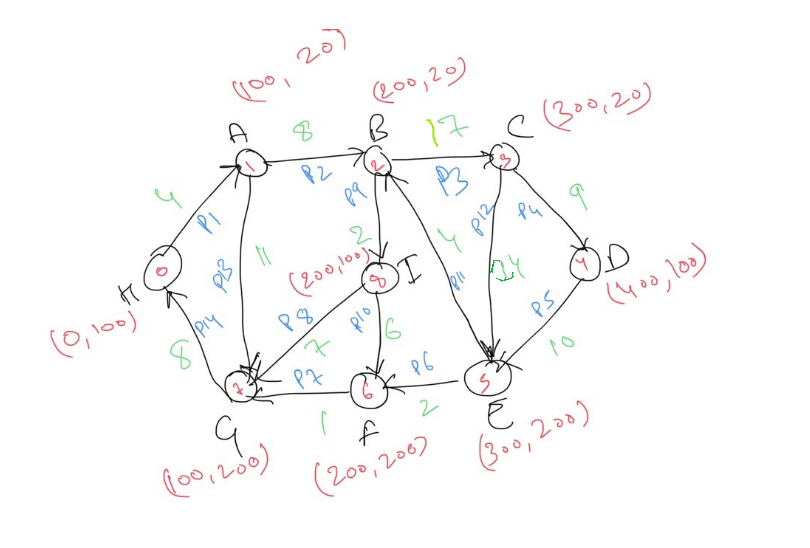
Sample Graph used the demo
Above graph that is fed to the Dijkstra algorithm to calculate the shorted path. Directions and costs are shown with the diagram. For the purpose of the demo video, node-0 is the start location and node-5 is the goal. Following video shows the boid travelling.
Dijkstra Demo
Performance
The performance of Dijkstra depends on the performance of the operations in open and close list. Ignoring the performance of the data structures, the performance of the algorithm is O(mn), where: n is each node in the graph that is closer that the goal node m is the average number of outgoing connections for each node. The primary drawback of the Dijkstra’s algorithm is that it searches the entire graph for the shortest possible route. This is useful if we want the shortest path to every possible node but wasteful if we want a point to point pathfinding. To counter this wastefulness, we use A* algorithm. A* Algorithm A* (A-Star) is designed for point to point pathfinding. It is similar to Dijkstra’s algorithm except for it uses Heuristics for better results. Heuristics, by definition, means ‘most likely.’ In A*, an estimated cost is associated with the node records and this estimated cost is used to move the algorithm forward. If heuristics are accurate, the algorithm will be efficient. If heuristics are terrible, it can perform even worse than the Dijkstra. Node Record has an additional entry for A* algorithm. Along with the cost so far (as in Dijkstra), we store estimated cost in the Node Record as well. In A*, we select a node with the smallest estimated total cost at each iteration (unlike cost so far as in Dijkstra). Unlike Dijkstra, A* can find better routes to nodes that are already on the closed list. This causes a knock-on problem. If estimates are very optimistic, then the node might be processed thinking it was the best choice (when it was not). We can avoid this by placing removing a node from the closed list and putting it back to the open list. Below steps can be used to describe the A* algorithm:
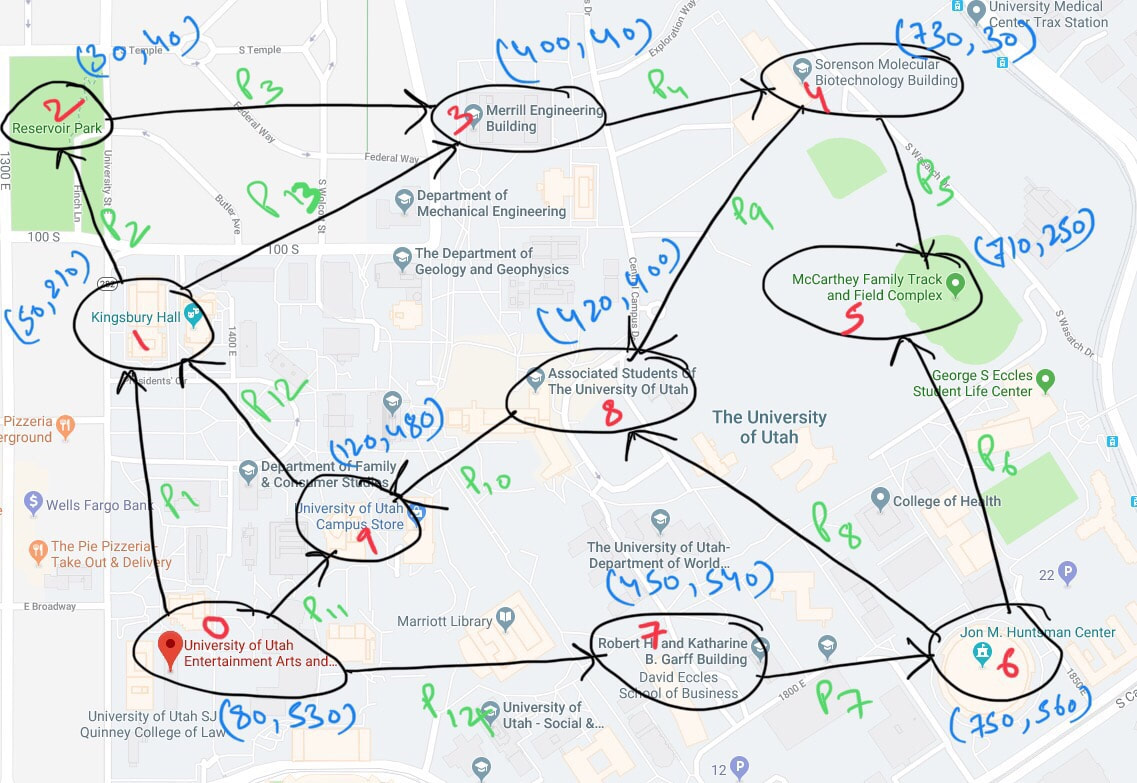
Sample graph used in A* demo algorithm. Nodes, connections, costs and directions are all set up randomly.
Above graph that is fed to the A* algorithm to calculate the shorted path. Directions and costs are shown with the diagram. For the purpose of the demo video, node-0 is the start location and node-5 is the goal. Following video shows the boid travelling.
A* Demo #1
In the next video, we the see that boid taking a different route if we remove one of the edge in the graph. As there was no connection, the algorithm spits out a different (shortest )path.
I have used Manhattan Heuristics for these demos of A*. A* Demo #2 Heuristics The estimates we use in the A* algorithm is called as Heuristic. I am using a Heuristics class in my program and using it get the Heuristics between two points. Heuristics are used to make an estimate between two nodes, and it might need some algorithmic processing. If the time spent calculating a heuristic is large, it might quickly dominate the pathfinding algorithm. Two different heuristics I have used in my algorithm are: Euclidian Distance: Sqrt((x1^2 + x2^2) + (y1^2 + y2^2)) Manhattan Distance: Abs(x2 - x1) + Abs(y2 - y1) Choosing an appropriate heuristic is essential for the A* start algorithm. While heuristics can underestimate or overestimate the costs, it is necessary to make them consistent. Overestimating doesn't exactly make the algorithm "incorrect"; what it means is that we no longer have an admissible heuristic, which is a condition for A* to be guaranteed to produce optimal behavior. With an inadmissible heuristic, the algorithm can wind up doing tons of redundant work. Overestimating can also lead to algorithm not returning the shortest path. With underestimation, A* will only stop exploring a potential path to the goal once it knows that the total cost of the path will exceed the cost of a known path to the goal. Since the estimate of a path's cost is always less than or equal to the path's real cost, A* can discard a path as soon as the estimated cost exceeds the total cost of a known path. I even tried inconsistent heuristics, i.e., some heuristics were overestimating, and some were underestimating. This also resulted in the algorithm not returning the shortest path. The case might arrive where a longer path to goal has shorter estimates. This will result in A* first processing the shorter estimate path to goal (longer cost in real) and the algorithm will terminate when it reaches the goal, thus returning ‘not’ shortest path. Note: If the heuristic always returns 0, then the estimated-total-cost will always be equal to the cost-so-far. When A* chooses the node with the smallest estimated-total-cost, it is choosing the node with the smallest cost-so-far. This is identical to Dijkstra. A* with a zero heuristic is the pathfinding version of Dijkstra. Real World Application Our path finding algorithms work on nodes and connections, but game worlds are not made of these nodes or connections. In order to make these algorithms work, we need some type of methodology to convert the space between game and graph world. To achieve this, we divide the game world into linked regions that corresponds to nodes and connections. Quantization: The process of converting world coordinates to graph nodes. Localization: The process of converting graph nodes to world coordinates. There are many division schemes we can use to divide our game world into nodes and connections. A division scheme is valid if all points in two connected regions can be reached from each other. In practice, division schemes don’t usually enforce this validity. I have used the tile graph division scheme in my program. Tile Graphs In this scheme, game world is divided into tiles. These tiles represent the nodes in the graphs. Connections are made between neighboring tiles. Such tile-based graphs are generated automatically. A tile-based graph does not need to store the connections for each node in advance. It can generate them as they are requested by the pathfinding algorithm. While it is easy to make tile-based graphs from a world level, they are not usually less accurate. Also, a game world can have large number of tiles which will affect the performance of the algorithm. It is up to us to decide what size of tile we want to use in our program. Tile size can vary from one tile per pixel to any number of units we set. It is important to find the right balance between time and accuracy with these tile graphs. While smaller tiles result in more accurate paths, they add a complexity to the pathfinding algorithms as there will be more nodes and connections to process. Larger tiles require less computational processing, but they are less accurate. It is dependent on the requirement of the game that should determine what tiling we choose. The following video shows the boid movement to the point of click. I am using the tile graph approach with obstacle marked as not accessible nodes. A* Demo #3
0 Comments
|
AuthorWrite something about yourself. No need to be fancy, just an overview. ArchivesCategories |
- Projects
- Prototypes
-
Blogs
- Sic Parvis Magna
- Game Engineering - Week 1
- Game Engineering - Week 2
- Game Engineering - Week 3
- Game Engineering - Week 4
- Game Engineering - Week 5
- Game Engineering - Week 6
- Game Engineering - Week 7
- Game Engineering - Week 8
- Game Engineering - Week 9
- Engine Feature - Audio Subsystem
- Final Project - GameEngineering III
- AI Movement Algorithms
- Pathfinding Algortihms
- Decision Makiing
- About
 RSS Feed
RSS Feed
Telephone801-859-1131
|
| ||||||